Building my own search engine
Why not just use Google?
I now what you’re thinking, “just google it”. And you see my dear reader you’re probably right. But where’s the fun in that?
From time to time I watch tsoding’s videos and he was working on a local search engine written in rust (seroost).
So I had that on the back of my mind. Looking for an excuse to build a search engine for my own purposes.
I recently discovered a podcast called linux unplugged which is part of a group of shows Jupiter broadcasting.
The problem is that currently there’s no way to search for specific episodes. And that’s why I’m building a search engine.
The plan
Now the Plan. Since this is my first time building a search engine I want to keep thing simple.
Ok a search engine should have the following features:
- Accept user input (the search query)
- Process the user input and transform it into something useful for searching (like search terms and keywords)
- Use the processed input to search against the episode data
In essence our search engine has the following jobs:
- Index / organize data to make it searchable
- Accept user input in the form of a query
- Use the query to actually search for episodes
- Rank and return the search results
The stack
- Rust: For the web server
- Python: For web scrapping & indexing the data
- Html & css & javascript: To make it look pretty
But first we need to get some data in order to search through it.
Web scrapping the data 🙈 🏴☠️
Web scrapping and data manipulation with python
If you hop over the linux unplugged website you’ll quickly see that we have everything we need from the start.
Using python to download and parse the site. For that I used requests and BeautifulSoup respectively.
With BeautifulSoup we should be able to extract every episode contained within a page (which is just html).
Every episode looks like this:
interface Episode {
title: string;
description: string;
date: string;
duration: number;
tags: string[];
}Organizing the data
A good way to model your data is to ask yourself: What kind of data am I dealing with?, What is the shape of data?.
Ideally you would like to organize episodes into categories,
like episode A talks about docker while episode B talks about nixos.
And you’d say that episode A goes into the docker category and episode B goes into the nixos category.
But episodes can have more than one category, meaning that they can appear more than once in a search so we need to account for that.
After transforming the page into a bunch of episodes, we’ll store them like:
- a map of episode id and episode
- a map of tag and episodes with that tag
type EpisodesById = Record<Id, Episode>;
type EpisodesByTag = Record<Tag, Episode[]>;Searching!
Let’s say we want to search an episode by it’s tag, to avoid looping through the whole list of tags we want to use a HashMap<Tag, Episode>.
⚠️ Disclaimer: Very basic stuff will be explained. ⚠️
If you are too deep for that please feel free to skip it.
The other option is to loop through every episode then loop through every tag. Say that we have 100 episodes and each episode has 20 tags approximately. (You might get bored if you know about for loops but bear with me for a bit).
Something like this:
let episodes = new Set<Episode>();
// foreach episode
for (let i = 0; i < 100; i++) {
// foreach tag
for (let j = 0; j < 20; j++) {
// check tag
// add <episode> to episodes set
}
}That’s 2000 operations. Now compare that with the following:
let episodes = new Set<Episode>();
for (const [tag, episodes] of episodes_by_tag) {
// check tag
// add <episodes> to episodes set
}The above is only 20 operations, we heavily depend on the Set to efficiently omit repeated episodes.
- “But that’s 20 tags we’re talking about thousands of tags!”
- Yes I’m aware of that, I was pointing out that we are avoiding 2000 operations.
Turns out that the shape of the loop matters. Who would have thought?
Back to the search algorithm
Once we have our HashMap, we can check if the tag exists and if it does you get all the episodes with that tag.
for (tag, episodes) in episodes_by_tag.iter() {
if terms
.iter()
.any(|term| tag.contains(term) || term.contains(tag))
{
results.extend(episodes.iter().map(|episode| (**episode).clone()));
}
}You: Fancy, but what if a tag is related to another tag? you could take advantage of that.
For example the tag docker is related to the tag docker-compose, but if we search for “docker” we can’t guarantee that we will get an episode related to docker-compose because of how we process the search query. And we could take advantage of that fact to reduce the number of searches. To be fair related tags tend to stick together (usually) so in theory it shouldn’t be a problem.
More features! what if the user wants to search for multiple tags? or maybe the user wants to search for an exact keyword that contains whitespace.
In this case we need to process the search query before using it. For that we’ll turn back to the dark magic of lexers and parsers. For example:
type SearchResults = Set<Episode>
function search(query: string): SearchResults {
...
}
search("docker .local nixos")terms = []
docker .local nixos
^-- keep going
...
docker .local nixos
^-- keep going
terms = [docker]
docker .local nixos
^-- found whitespace! add 'docker' to terms
terms = [docker, .local]
docker .local nixos
^-- found whitespace! add '.local' to terms
terms = [docker, .local, nixos]
docker .local nixos
^-- found whitespace! add 'nixos' to termsAn example with ""
terms = []
"docker compose" nixos
^-- found " keep going until we find another "
terms = []
"docker compose" nixos
^-- found " add 'docker compose' to termsWith the parser working we have extracted the keyword / search terms from the search query. Now we’ll use that to search for more episodes. We could (and probably should) add support for more operators but I think this is ok for now.
Searching by titles 🔎
What if the user searches an episode not by tag, not by id, just by title or a partial title? Remember that section that you TOTALLY didn’t skip, well we’ll break every rule in the book for learning purposes.
You see, the thing is we didn’t store the episodes by it’s title so the only way we have to know if a term is inside a title is by looping through all the episodes.
Yep that doesn’t spark joy to me ✨🥹. But we’ll do it anyways.
Here’s the code
for (id, episode) in state.episodes_by_id.iter() {
if results.contains(episode) {
continue;
}
let episode_id = id.to_string();
if terms.contains(&episode_id)
|| terms
.iter()
.any(|term| episode.title.to_lowercase().contains(term))
{
results.insert(episode.clone());
}
}But this time is different
- Most of the episodes are already on the search results
Set - Loops
ntimes, wherenis the number of episodes and notn* number of tags
Ranking system
With our search engine in a functional state, the only thing left to do is to return the search results. But before doing that we need to figure out a way to sort the results, a ranking system you want. Keep in mind that some episodes suit better the search terms than others.
For that purpose I arbitrarily decided to give 50 points for every search term that matched a tag and 100 points for every search term that matched the title.
The code for the ranking system:
let mut results_with_score: Vec<_> = results
.iter()
.map(|episode| {
let mut score = episode.tags.iter().fold(0, |acc, tag| {
// scores for tag
acc + if terms.contains(tag) || terms.iter().any(|term| tag.contains(term)) {
50
} else {
0
}
});
// scores for title
score += terms.iter().fold(0, |acc, term| {
acc + if episode.title.to_lowercase().contains(term) {
100
} else {
0
}
});
(score, episode)
})
.collect();We iterate over the results, we map every episode tag to a score, 50 if the tag matches the search term else 0. After that we iterate over the search terms, we map every episode title to a score, 100 if there’s a match else 0. At the end we return a tuple of score and episode. And with that. We can Finally return the search results to the user:
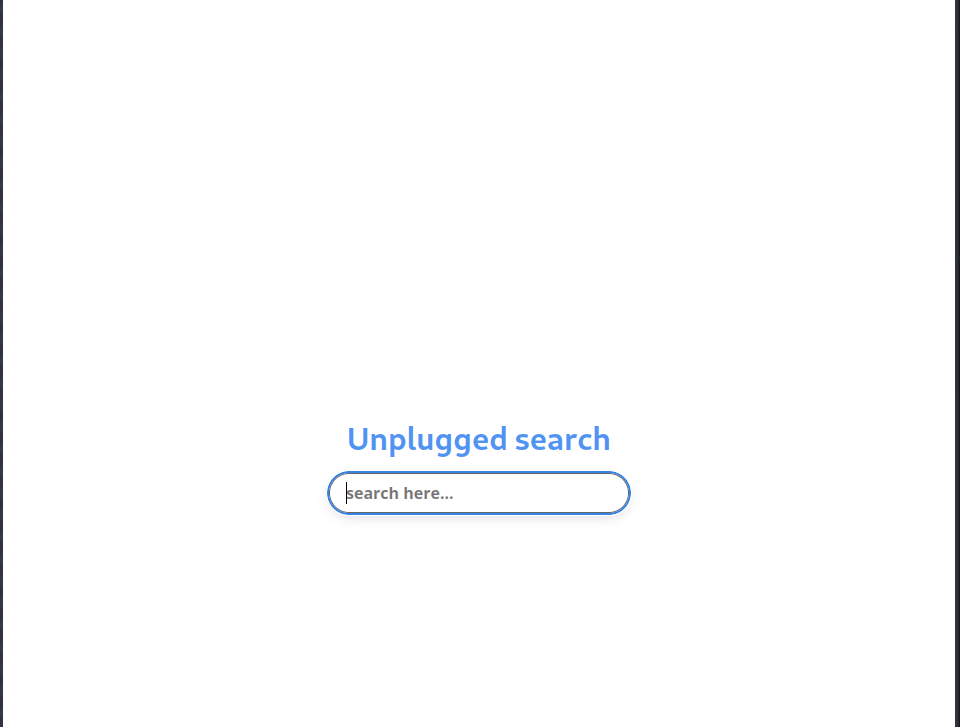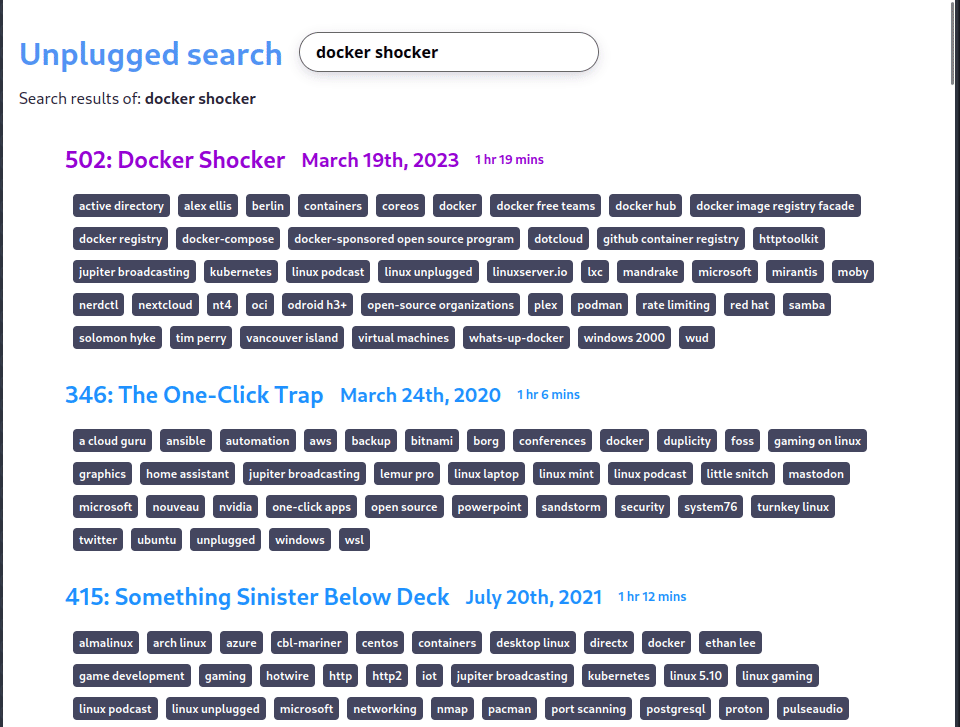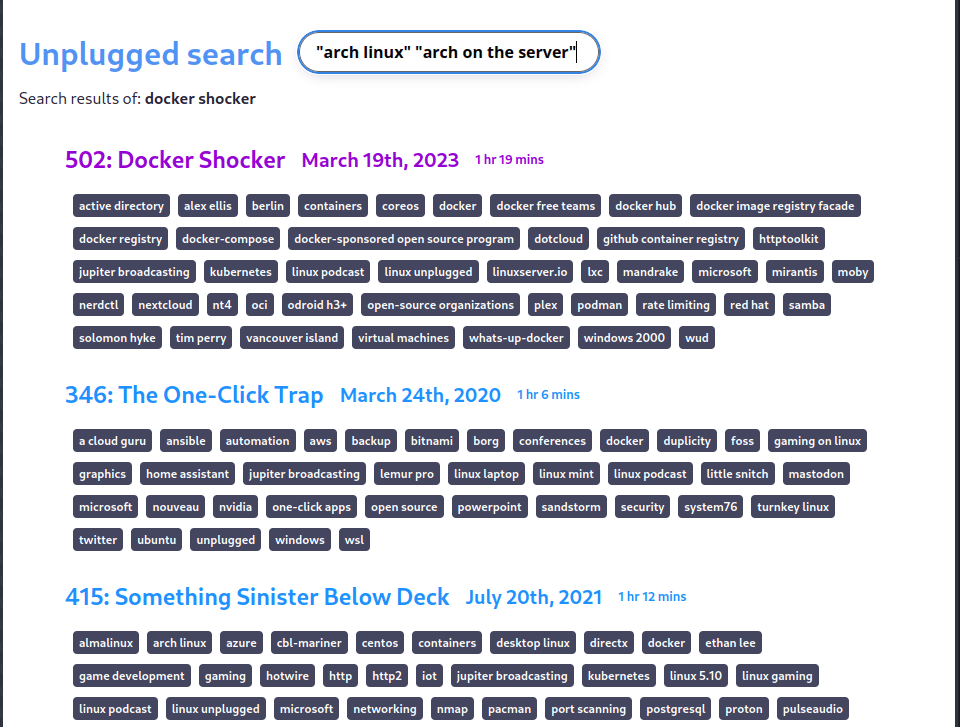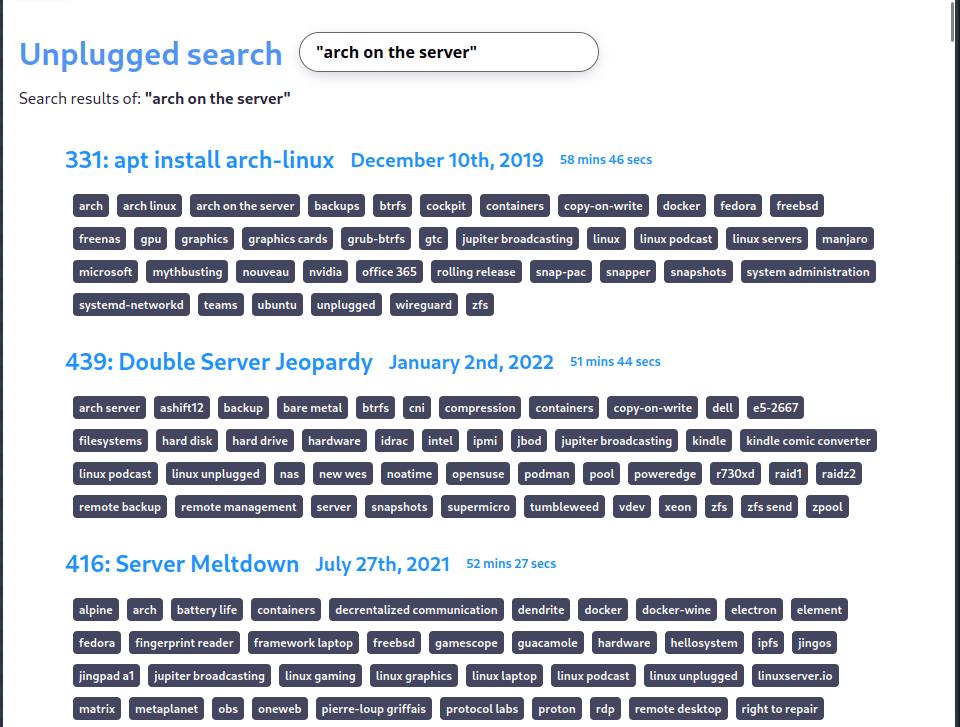
Optimizations that I’m planning to add
Searching partial tags
Now. What if we only get partial tags from the user?
For instance:
query("do dir");
// do -> [docker, docker-compose, dotnet, dos, download]
// dir -> [directory, direnv, dirty, directx, dirk, disc]In order to quickly search the beginning of a tag we could ask for help to our friends, the trees. You know they’re green and tall, they release oxygen. And for some reason people have a tendency to invert them.
But now we search for the do keyword:
keyword: "do"
(do)
/ \
(docker) (dot)
/ \
(docker compose) (dotnet)Text editors autocomplete words using a similar trick. (I can’t remember the name of it. Sorry)
We use a binary tree to store partial tags, which means we reduce the amount of tags we have to loop through.
The exclude operator
ubuntu -"arch linux" # exclude "arch linux" (but not the term linux) from search results
fedora -nixos # exclude nixos from search resultsConclusions
- Thinking about the shape of the data we’re dealing with is part of the job and can make thing easier.
- Building things yourself can be a good learning exercise.
- The shape of the loop matters.
- There’s always room for improvement.